
 Contacte
Contacte




Autor: Dr. Joan Nunes. Universitat Autònoma de Barcelona
Promotor: Institut Cartogràfic de Catalunya, 2013
L'estadística espacial comprèn el conjunt de mètodes de caràcter estadístic que tenen explícitament en compte la dimensió espacial de les dades i les relacions espacials entre les observacions. En concret, i en particular, els mètodes d'estadística espacial incorporen l'associació o influència que poden tenir les localitzacions entre elles o els valors mesurats en les localitzacions, generalment en forma de pesos. En aquest sentit, l'anàlisi de l'autocorrelació espacial, o grau de dependència espacial dels fenòmens, és una part fonamental i característica de l'estadística espacial, per si mateixa i com a base d'altres mètodes d'anàlisi específics.
L'estadística espacial forma part de l'anàlisi espacial i sovint se l'ha considerat com el nucli més característic de l'anàlisi espacial, fins al punt que alguns autors de la tradició geogràfica quantitativa presenten ambdues com una mateixa cosa. Tanmateix, l'anàlisi espacial és més àmplia i comprèn, a més de l'estadística espacial i la geoestadística, altres tipus de mètodes no estadístics, com és ara les diverses classes de models matemàtics, estocàstics o dinàmics, l'anàlisi de xarxes, les tècniques geomètriques o els índexs de configuració espacial. L'estadística espacial, d'altra banda, està relacionada amb la geoestadística, però se'n diferencia pel fet de tenir un propòsit més general, mentre que la geoestadística té per objecte principal i gairebé exclusiu la interpolació espacial de superfícies mitjançant la modelització estadística del component aleatori del fenomen estudiat.
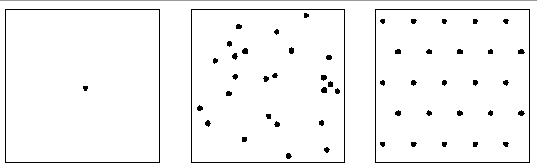
Exemples de distribucions de punts. a) completament agrupada; b) aleatòria; c) completament regular.
Origen
L'estadística espacial té els seus orígens a la dècada de 1950. Els primers treballs, significativament dedicats a l'anàlisi de l'autocorrelació espacial (Moran, 1950; Geary, 1954), provenen del camp de la mateixa estadística. Paral·lelament, des de la biologia i l'ecologia, apareixen també en aquesta dècada les primeres formulacions sobre la variació espacial estacionària (Whittle, 1954) i més tard, ja en la dècada de 1960, s'hi afegirien aportacions des de l'epidemiologia o l'economia.
En el camp de la geografia, l'estadística espacial s'introduí i desenvolupà arran de l'anomenada revolució quantitativa en geografia, a partir de la dècada de 1960, amb treballs significatius i tan influents com el recull de mètodes de Hagget (1965). Bona part d'aquests mètodes quantitatius, però, no es poden considerar pròpiament mètodes d'estadística espacial i ni tan sols mètodes d'anàlisi espacial, sinó simplement l'aplicació de mètodes estadístics generals a dades geogràfiques, sense fer intervenir necessàriament la localització en les anàlisis. El desenvolupament de mètodes d'estadística espacial pròpiament dits tindria lloc sobretot a la dècada de 1970 i posteriorment, després d'un cert estancament a la dècada de 1980, al llarg de la dècada de 1990 amb renovada intensitat i especialització. La incorporació dels mètodes d'estadística espacial en els sistemes d'informació geogràfica (SIG) a finals de la dècada de 1990 i al llarg de la dècada de 2000 ha contribuït a difondre'n l'ús i revitalitzar-ne l'interès, tot ampliant la capacitat analítica dels sistemes d'informació geogràfica de manera significativa.
Definició
L'estadística espacial es caracteritza pel fet d'emprar mètodes genuïnament estadístics. En particular i principalment, utilitza el contrast entre les distribucions espacials empíriques dels fenòmens estudiats i distribucions de probabilitat teòriques, mitjançant proves de significació que, com els tests d'estadística inferencial clàssica, inclouen càlcul d'estadístics, formulació d'hipòtesis nul·la i alternativa, càlcul de la probabilitat de compliment de la hipòtesi nul·la i elecció de nivells de significació o de confiança. Així mateix, igual que l'estadística general, l'estadística espacial inclou també mètodes descriptius per a sintetitzar els patrons de distribució o de variació espacial i mètodes predictius basats en l'ajust de models obtinguts a partir de les observacions.
L'estadística espacial, però, a diferència de l'estadística convencional, incorpora explícitament i de forma quantificada la posició i les relacions espacials en la formulació dels estadístics que utilitza. Així, en el càlcul de molts dels estadístics emprats en estadística espacial es requereix establir la importància relativa que té la relació espacial o posició relativa entre cada parell d'observacions en la variació del fenomen en cada posició.
Aquest és el tret distintiu de l'estadística espacial respecte de l'estadística convencional, que dóna lloc a tipus i mètodes d'anàlisi propis. L'aplicació de mètodes d'estadística convencional a dades espacials, que posseeixen localització, no forma part de l'estadística espacial, malgrat que erròniament sovint s'hagi presentat com a tal en la tradició quantitativa en geogràfica.
Objecte de l'estadística espacial. Tipus d'anàlisis
L'estadística espacial té per finalitat principal dos tipus específics d'anàlisis: l'anàlisi dels patrons de distribució espacial de les localitzacions dels objectes o entitats i l'anàlisi de la variació espacial dels atributs dels objectes o entitats. En el primer cas s'analitzen únicament les posicions dels objectes o observacions. En el segon cas s'analitzen els valors d'un atribut dels objectes o observacions tenint en compte la posició corresponent a cada valor.
En tots dos casos, intervé la posició de les observacions mitjançant la relació espacial o posició relativa d'unes observacions respecte de les altres, per tal d'aplicar en l'anàlisi el pes o factor adequat a la relació espacial entre cada parell d'observacions.
L'anàlisi dels patrons de distribució espacial de les localitzacions dels objectes o entitats, per simplificar anàlisi de distribucions espacials, generalment s'ha limitat a l'anàlisi de distribucions de punts (point pattern analysis) per la major simplicitat d'especificació i càlcul de relacions espacials.
L'anàlisi de la variació espacial dels atributs dels objectes o entitats, o simplement anàlisi de la variació espacial, s'aplica igualment a dades d'atributs corresponents a punts o a àrees que formen una partició regular (per exemple, les cel·les d'un ràster) o irregular (per exemple, un conjunt d'unitats administratives com és ara els municipis) de l'espai. Dins de l'anàlisi de la variació espacial s'inclou l'anàlisi de l'autocorrelació espacial, que és un dels trets més característics de les dades espacials.
La següent és, a grans trets, una classificació no exhaustiva dels principals mètodes d'estadística espacial:
- Anàlisi de distribucions espacials
- Anàlisi de patrons de distribució espacial
- Anàlisi de quadrats
- Anàlisi del veí més proper
- Mètodes d'anàlisi basats en àrees de proximitat
- Anàlisi d'agrupaments espacials
- Anàlisi d'agrupaments espacials
- Funció de Ripley. Agrupament espacial a intervals de distància
- Anàlisi de patrons de distribució espacial
- Anàlisi de la variació espacial d'atributs temàtics d'entitats
- Mesures descriptives de la variació espacial
- Centre mitjà
- Centre medial
- Punt central
- Distància estàndard
- Distribució direccional (el·lipse de desviació estàndard)
- Mitjana direccional lineal
- Anàlisi de patrons de variació espacial
- Autocorrelació espacial
- Regressió lineal ordinària
- Regressió ponderada geogràficament
- Anàlisi d'agrupaments de la variació espacial
- Índex G general de Getis-Ord
- Índex Gi* de Getis-Ord
- Índex d'Anselin d'autocorrelació espacial local
- Mesures descriptives de la variació espacial
Quantificació de les relacions espacials. La matriu de pesos espacials
El pes atorgat a la relació espacial entre cada parell d'observacions es recull en l'anomenada matriu de pesos espacials, la qual es pot establir prenent com a base diferents tipus de relacions espacials (Getis and Aldstadt, 2004). En el cas més simple, per a dades d'atributs corresponents a àrees, en què la relació espacial considerada és la contigüitat entre àrees, pren el nom també de matriu de contigüitat, denominació que, per extensió, s'utilitza també com a sinònim de matriu de pesos espacials.
La matriu de pesos espacials és una representació de l'estructura espacial de les dades. Concretament és una quantificació de les relacions espacials entre les entitats o observacions analitzades o, si més no, una quantificació de la forma en què hom les ha conceptualitzat. En aquest sentit, cal escollir la conceptualització, és a dir la relació espacial, que reflecteixi millor la importància relativa de la posició en la variació espacial i la manera més apropiada de quantificar-la. Per exemple, en el cas d'analitzar l'agrupament espacial d'una espècie vegetal que es propaga per dispersió aèria de les llavors, la forma més apropiada de quantificar la relació espacial entre diferents posicions pot ser una funció de la distància inversa. En canvi, per a analitzar la distribució espacial dels desplaçaments a una destinació, serà més apropiat utilitzar com a quantificació el temps o el cost de desplaçament entre localitzacions a través de la xarxa de transport.
Tal com el nom indica, la matriu de pesos espacials és una matriu o taula d'orígens-destins, que recull el pes o valor quantificat de la relació espacial entre tots i cada un dels parells de localitzacions de les entitats o observacions analitzades.
La quantificació de les relacions espacials depèn del tipus de relació espacial i del mètode de quantificació, que pot ser binari o ponderat. En el mètode binari, per exemple per a relacions espacials de contigüitat o de rang de distància fix, els valors 0 o 1 simplement denoten si hi ha o no relació entre un determinat parell d'entitats o observacions en funció de la seva posició i si, per tant, el parell intervé o no en el càlcul de l'estadístic espacial. En el mètode ponderat, per exemple en base a la distància inversa, cada parell d'entitats o observacions rep un pes variable calculat per mitjà d'alguna funció de les seves respectives posicions, típicament algun tipus de distància. Per simplificar, se sol anomenar veïns en el sentit més ampli del terme a cada parell d'entitats o observacions relacionades espacialment. En el cas de la relació espacial de contigüitat, efectivament els "veïns" són pròpiament veïns. Aquesta terminologia prové dels primers índexs d'anàlisi de l'autocorrelació espacial, que utilitzaven inicialment la relació de contigüitat entre àrees.
Alguns dels tipus de relacions espacials i formes de quantificació utilitzats habitualment són la distància inversa; un rang de distància fix; els K veïns més propers, la contigüitat i la triangulació de Delaunay. Pel que fa a distàncies, les més emprades són la distància euclidiana, la distància de Manhattan i la distància de xarxa, que proporciona una mesura més realista de les posicions relatives en l'espai que la distància en línia recta (per exemple, en espais urbans o en processos que tenen lloc a través de la xarxa de transports). La combinació de relació espacial, distància i mètode de quantificació dóna lloc a un cert nombre de variacions que es revisen tot següit.
Distància inversa
La quantificació per mitjà de la distància inversa o de la distància inversa al quadrat correspon a una relació espacial de decaïment amb la distància. En aquesta manera de conceptualitzar la relació espacial les entitats o observacions, totes les entitats estan relacionades i per tant s'influencien mútuament, però aquesta influència és tant més feble com major és la distància entre les localitzacions de les entitats o observacions. Concretament, i d'acord amb la funció de proporcionalitat inversa, la influència és forta a distàncies properes i decau molt ràpidament en molt poca distància per mantenir-se després a nivells baixos que continuen disminuint de forma molt gradual. Sovint, s'aplica un llindar de distància, a partir del qual el pes es considera 0, per limitar l'abast de la relació a les distàncies significatives i reduir les necessitats de càlcul. En el cas d'utilitzar la distància inversa al quadrat, el comportament de la funció de quantificació és el mateix però el valor dels pesos decau encara més ràpidament amb la distància, de manera que només les localitzacions més properes exerceixen una influència significativa. Aquest mètode de càlcul de la matriu de pesos espacials permet utilitzar qualsevol distància (euclidiana, de Manhattan o de xarxa) en funció del fenomen estudiat. La distància inversa és un mètode apropiat per a fenòmens que varien de forma contínua en l'espai, de manera que cada localització rep la influència de la resta però de forma decreixent segons la distància. Assigna a cada punt un pes ponderat.
Rang de distància fix
Una distància fixa estableix una àrea d'influència d'un determinat abast al voltant de cada localització, dins del qual existeix relació. Fora d'aquesta àrea o rang de distància la relació cessa bruscament. La quantificació en aquest cas sol ser binària i atorga un pes d'1 per igual a totes les localitzacions dins de l'àrea d'influència i de 0 a totes les que són fora d'aquesta àrea. El rang de distància fix és conceptualment equivalent a una finestra mòbil o veïnat d'abast fix.
El mètode de distància fixa s'utilitza per analitzar la variació espacial de les dades a un determinat rang de distància, si es coneix a priori, o a diferents rangs de distància repetint l'anàlisi per a diferents distàncies fixes. És un mètode apropiat per a dades associades a àrees que varien molt en forma i grandària. Assigna a cada punt un pes binari.
La distància inversa i el rang de distància fix es poden utilitzar per separat o combinar de diferents maneres. Un rang de distància fix pot servir per limitar l'aplicació del càlcul de la distància inversa fixant un llindar de distància o àrea d'influència dins la qual s'aplica la distància inversa, o a l'inrevés pot servir per excloure una primera àrea indiferent, dins la qual el pes és màxim, i després aplicar la distància inversa.
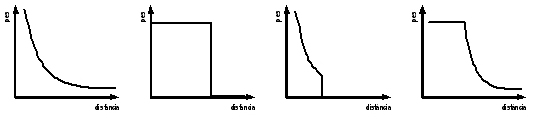
Diferents mètodes de quantificar el pes de les relacions espacials segons la distància. a) distància inversa; b) rang de distància fix; c) distància inversa limitada per llindar de distància; d) àrea indiferent més distància inversa. Font: Elaboració pròpia.
K veïns més propers
Una altra manera de definir i conceptualitzar el context espacial en què s'avaluen les relacions espacials que condicionen la variació espacial dels fenòmens, és definir el veïnat d'anàlisi per mitjà d'un nombre determinat de localitzacions veïnes, els K veïns més propers, a cada localització, en lloc d'utilitzar la contigüitat o una funció fixa o variable de la distància. Aquest mètode té l'avantatge d'adaptar-se per si mateix a tot tipus de distribucions espacials. En el cas que hi hagi una alta densitat d'observacions, un nombre fix de veïns limita el context espacial de l'anàlisi a una distància relativament petita, mentre que en una situació amb observacions disperses, el nombre fix de veïns estén el veïnat a una distància més gran. En els casos en què les observacions es distribueixen de manera uniforme en l'espai, com per exemple les cel·les d'un ràster, un nombre fix de veïns és pràcticament equivalent a una distància fixa. El mètode té l'avantatge addicional que, independentment de la densitat d'observacions, sempre s'assegura l'existència de veïns per a calcular la matriu de pesos espacials. Un nombre de veïns fix és un mètode apropiat per a dades que presenten una distribució desigual i irregular en l'espai, ja que assegura l'existència de veïns en tots els casos, però pot sobrevalorar la influència de localitzacions allunyades. Assigna a cada punt un pes binari.
Triangulació de Delaunay
La triangulació de Dealunay és el resultat de dividir l'àrea d'estudi coberta per un conjunt de punts (o els centroides d'un conjunt d'àrees o de línies) en àrees de proximitat (polígons de Thiessen) i formar triangles unint cada punt (o centroide) amb els punts més propers a aquell punt que a qualsevol altre. D'aquesta manera es determina de forma variable quants i quins són els veïns més propers a cada punt (tots els punts units per arestes de triangle a un punt donat). Igual que el mètode de K veïns més propers, la triangulació de Delaunay s'adapta a la densitat de les entitats o observacions i assegura sempre l'existència d'algun veí, però té l'avantatge addicional de no imposar un nombre de veïns fix per a cada punt, sinó de determinar els veïns més propers en cada cas. La triangulació de Delaunay està considerada per alguns autors com el mètode per identificar els veïns naturals en un conjunt de punts o d'elements geomètrics, ja que identifica els veïns més propers a cada punt que a la resta de punts i no imposa rangs de distància ni nombre de veïns. És apropiat per a dades distribuïdes de forma irregular a l'espai. Assigna a cada punt un pes binari.
Contigüitat
Per a l'anàlisi de la variació espacial d'atributs associats a àrees, el mètode bàsic i original de considerar les relacions espacials que condicionen la variació dels valors és la contigüitat, de manera que els polígons adjacents a cada polígon es tenen en compte i la resta no, mitjançant l'assignació de pesos 1 o 0, respectivament, en la matriu de pesos espacials. En algunes implementacions s'ofereix l'opció de considerar dos polígons adjacents no sols quan comparteixen una vora comuna sinó també quan comparteixen només un punt. Aquestes dues opcions són habituals a l'hora de definir les cel·les veïnes en el cas de les dades ràster (configuració de torre i configuració de dama, respectivament). És un mètode apropiat per a dades associades a àrees de forma i grandària similars. Assigna a cada punt un pes binari.
Anàlisi de distribucions espacials
L'anàlisi de distribucions espacials analitza només la posició de les entitats o de les observacions i inclou dos grans tipus d'anàlisis: l'anàlisi de patrons de distribució espacial mitjançant el contrast amb distribucions de probabilitat teòriques i l'anàlisi que té per objecte la formació o la descripció d'agrupaments espacials.
Anàlisi de patrons de distribució espacial
L'anàlisi dels patrons de distribució espacial, generalment limitada a l'anàlisi de distribucions de punts, comprèn diversos mètodes que tenen per finalitat proporcionar un índex o mesura de la forma global de la distribució espacial en relació al patró aleatori, juntament amb el grau de significació de la divergència respecte d'aquest patró.
Anàlisi de quadrats
L'anàlisi de quadrats és un mètode d'anàlisi de patrons de distribució espacial de punts que es basa en el recompte del nombre de punts dins de cada un dels quadrats en què es divideix una àrea d'estudi. L'anàlisi de quadrats compara les freqüències observades de nombre de quadrats amb 0, 1, 2,..., n punts amb les esperades per a cada una d'aquestes categories de nombre de punts segons una distribució de probabilitat teòrica que reflecteixi adequadament el tipus de procés que dóna lloc a la distribució espacial dels punts.
Una de les distribucions de probabilitat teòriques més simples és la distribució de Poisson, que correspon al patró d'aleatorietat perfecta i que es calcula d'acord amb la fórmula següent:
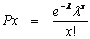
on
Px és la probabilitat de trobar x punts en un quadrat segons patró espacial generat per un procés aleatori (Px es calcula successivament per a x = 0, 1, 2,...)
λ és la mitjana esperada de nombre de punts per quadrat (nombre total de punts observats dividit pel nombre total de quadrats)
Els valors de probabilitat obtinguts es converteixen en freqüències esperades multiplicant cada probabilitat pel nombre de quadrats. Les freqüències esperades es poden comparar aleshores amb les freqüències observades per mitjà del test de χ2, amb m-2 graus de llibertat (essent m el nombre de categories de nombre de punts per quadrat).
A part de la distribució de Poisson, que és la mes simple, s'utilitzen moltes altres distribucions de probabilitat teòriques, que combinen la distribució de Poisson amb altres processos més complexos, de forma additiva o multiplicativa (per exemple, la distribució de Bernouilli, la distribució binomial negativa, la distribució A de Neyman o la doble distribució de Poisson, entre d'altres). Les primeres aplicacions del mètode d'anàlisi de quadrats són força antigues (Matui, 1932), però la majoria són de la dècada de 1960 i 1970.
La mida dels quadrats té efectes crítics sobre els resultats i, per bé que existeixen propostes de definició òptima, l'elecció final de la mida resulta sempre arbitrària en major o menor grau. Les principals aplicacions de l'anàlisi de quadrats es troben en geografia quantitativa i també en ecologia del paisatge.
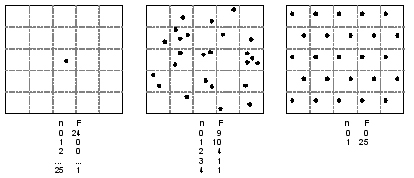
Anàlisi de quadrats. Freqüències observades (nombre de quadrats, F, de cada nombre de punts, n) de diferents tipus de distribucions espacials: a) completament agrupada; b) aleatòria; c) completament regular.
Anàlisi del veí més proper
L'anàlisi del veí més proper permet determinar el patró de distribució espacial d'un conjunt de punts, mitjançant el càlcul de la distància entre cada punt i el seu veí més proper. L'anàlisi del veí més proper calcula després la mitjana de les distàncies entre cada punt i el seu veí més proper, com una simple mitjana aritmètica:
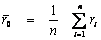
on ri és la distància entre el punt i i el seu veí més proper
La mitjana de les distàncies entre cada punt i el seu veí més proper, r- , és un estadístic que per a distribucions de punts aleatòries varia d'acord amb una distribució normal de mitjana E(r-) i desviació estàndard σr- conegudes. Una prova senzilla de significació estadística de la desviació del valor observat de r- respecte del valor teòric segons la distribució normal s'obté mitjançant el càlcul del valor normalitzat z de r- :
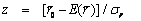
L'anàlisi del veí més proper va ser ideat a mitjan dècada de 1950 en el camp de l'ecologia (Clark and Evans, 1954) i poc després adoptat en geografia quantitativa (Dacey, 1960).
Mètodes d'anàlisi basats en àrees de proximitat
Com a alternatives a l'anàlisi de quadrats i a l'anàlisi del veí més proper s'han proposat, entre d'altres, mètodes d'anàlisi de distribucions de punts basats en polígons de Thiessen (Meijerink, 1953), que divideixen l'espai en àrees de proximitat centrades en cada un dels punts, o en els triangles d'una triangulació de Delaunay (Vicent et al., 1976), que és l'estructura dual derivada dels polígons de Thiessen.
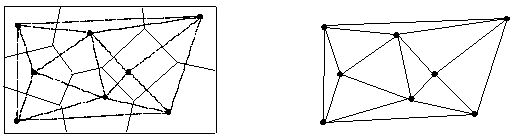
Àrees de proximitat. a) polígons de Thiessen; b) triangulació de Delaunay.
En ambdós casos,els mètodes proposats es basen en el càlcul de paràmetres descriptius dels polígons o bé dels triangles, que es poden contrastar amb els valors teòrics corresponents a patrons de distribució generats per processos aleatoris o altres.
L'avantatge d'aquests mètodes prové del fet que són independents de l'escala, ja que no pressuposen una unitat d'anàlisi arbitrària com els quadrats ni depenen de la densitat de punts (dependent de l'àrea i per tan de l'escala) per al càlcul dels paràmetres.
Anàlisi d'agrupaments espacials
A diferència de l'anàlisi de distribucions de punts, l'anàlisi d'agrupaments espacials no cerca donar una mesura que caracteritzi la forma de la distribució espacial en el seu conjunt, sinó identificar els agrupaments espacials presents en la distribució.
Anàlisi d'agrupaments segons la distància
Una de les formes més immediates d'anàlisi d'agrupaments espacials és aplicar directament els mètodes d'anàlisi d'agrupaments (cluster analysis), emprats en classificació estadística multivariable, a l'agrupament o "classificació" dels punts segons les seves coordenades espacials. Així, la distància que en la classificació estadística és la semblança o proximitat dels individus en l'espai abstracte de n dimensions definit per les variables considerades, en aquest cas és la distància espacial determinada per l'espai pròpiament dit de coordenades x, y (i eventualment z i/o t), que actuen com a variables i que en aquest cas són realment ortogonals.
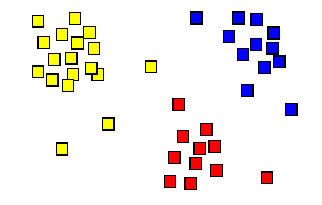
Anàlisi d'agrupaments espacials. Agrupament dels punts en tres grups segons la distància entre punts.
En aquest sentit, són aplicables tots els tipus d'anàlisi d'agrupaments (jeràrquica i no jeràrquica) i d'algorismes habitualment emprats en classificació estadística. Un dels més habituals és el mètode de k mitjanes o mètode basat en centroides, que agrupa els punts de tal manera que es minimitzi la distància de cada punt al centroide del grup de punts, definit per les mitjanes de les diverses variables o, en aquest cas, de les coordenades x i y. El resultat de qualsevol d'aquests mètodes són els grups de punts obtinguts segons la distància entre punts.
Funció de Ripley. Agrupament espacial a intervals de distància
L'anàlisi d'agrupament espacial a intervals de distància determina si les entitats o les observacions presenten un agrupament estadísticament significatiu a diferents intervals de distància. El mètode es pot utilitzar tant per a la informació de posició de les entitats o observacions com per als valors d'un atribut associat a les entitats o observacions.
L'anàlisi d'agrupament espacial a intervals de distància es basa en la funció K de Ripley (Getis, 1984; Boots and Getis, 1988; Bailey and Gatrell, 1995), o a efectes d'anàlisi de dades en la funció L(d), que és la funció K de variància estabilitzada, Les funcions K i L de Ripley mesuren la desviació de la distribució espacial d'un conjunt de punts respecte del patró d'homogeneïtat, que correspon al patró de distribució aleatòria, modelitzat de forma simple per la distribució de Poisson, i que es pot descriure intuïtivament com aquella distribució dels punts en una àrea tal que qualsevol cercle d'una determinada superfície dins d'aquesta àrea conté sempre aproximadament el mateix nombre de punts.
La funció L(d) de Ripley es defineix segons la fórmula següent:
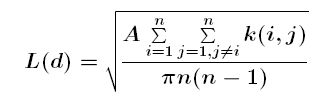
on
d és la distància
n és el nombre de punts
A és la superfície ocupada pel conjunt dels punts
k(i, j) és el pes espacial aplicat a la relació espacial entre les localitzacions i i j
La funció L(d) de Ripley proporciona un valor per a cada distància considerada. En aquest sentit es diferència d'altres mètodes, ja que en lloc de proporcionar un valor global del grau d'agrupació, descriu el grau d'agrupació a diferents intervals de distància. L'avantatge d'aquest mètode és el fet que no pressuposa l'elecció d'una escala apropiada d'anàlisi, sinó que permet explorar en quines distàncies (és a dir, escales) actua de forma predominant un determinat procés espacial. D'altra banda, és molt sensible al valor de superfície indicat per a l'àrea d'estudi, ja que la funció L(d) de Ripley és essencialment una funció de la densitat de punts. També tendeix a subestimar les localitzacions prop de les vores de l'àrea d'estudi.
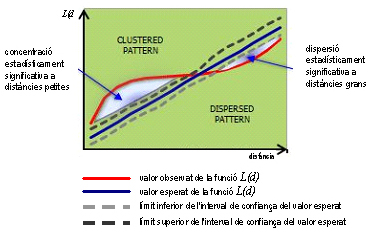
Anàlisi d'agrupament espacial a intervals de distància. Variació de la funció de Ripley amb la distància.
Per a cada distància considerada, s'obté el valor observat i el valor esperat de la funció, juntament amb els límits inferior i superior de l'interval de confiança de la funció. Quan el valor observat de la funció per a una determinada distància és més gran que l'esperat, la distribució és més agrupada que la distribució aleatòria en aquest rang de distància i és estadísticament significatiu si supera el límit superior de l'interval de confiança. Contràriament la distribució de punts és més dispersa que la distribució aleatòria en un determinat rang de distància quan el valor observat de la funció és inferior que el valor esperat.
Anàlisi de la variació espacial
L'anàlisi de la variació espacial analitza la variació en l'espai dels atributs de les entitats o de les observacions tenint en compte el context espacial de cada valor per mitjà d'un pes espacial, que expressa la importància relativa d'altres valors en altres posicions respecte al valor. Dins d'aquest tipus d'anàlisi s'inclouen estadístics descriptius de les distribucions espacials dels valors, l'anàlisi dels patrons de variació espacial entre els quals hi ha l'anàlisi de l'autocorrelació espacial, i l'anàlisi d'agrupaments de la variació espacial dels valors.
Mesures descriptives de la variació espacial
Igual que l'estadística convencional, l'estadística espacial disposa d'un cert nombre d'estadístics descriptius de les principals característiques d'una distribució espacial (centralitat, dispersió, etc.). Molts d'aquests estadístics espacials són homòlegs dels estadístics descriptius clàssics, però prenent en consideració la posició de cada valor.
Centre mitjà
El centre mitjà és l'homòleg espacial de la mitjana aritmètica d'una distribució no espacial de valors. Es pot calcular només per a les posicions dels punts o elements de la distribució espacial o també per als valors d'un atribut associat a les entitats o les observacions representades pels punts o pels elements.
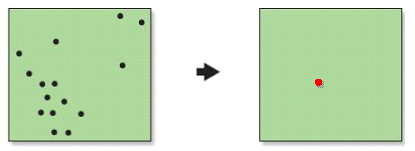
Centre mitjà d'una distribució espacial: mitjana de les coordenades dels punts de la distribució espacial.
El centre mitjà es calcula simplement com la mitjana de les coordenades x, y dels punts (o dels centroides dels elements) de la distribució espacial, per la qual cosa sovint s'anomena també centroide. En el cas de considerar també els valors d'un atribut, es calcula la mitjana de tots els valors dels punts o elements de la distribució espacial i s'associa al punt de coordenades mitjanes o centre mitjà de la distribució espacial. És l'estadístic espacial bàsic per a descriure la centralitat o tendència central d'una distribució espacial.
Centre medial
El centre medial és també un estadístic espacial descriptiu de la tendència central d'una distribució espacial de punts (o d'elements geomètrics, considerant els centroides dels elements). Es defineix com el punt que minimitza la distància euclidiana respecte de tots els punts de la distribució espacial. En el cas de considerar també els valors d'un atribut, es calcula la mediana de tots els valors dels punts o elements de la distribució espacial i s'associa al centre medial de la distribució espacial. El centre medial és menys sensible que el centre mitjà a la presència de punts anòmals, molt allunyats de la resta.
Punt central
El punt central o element central és el punt (o el centroide dels elements geomètrics) de la distribució espacial que minimitza la suma de distàncies respecte de tots els altres punts.
L'element central és també un estadístic espacial descriptiu de la tendència central.
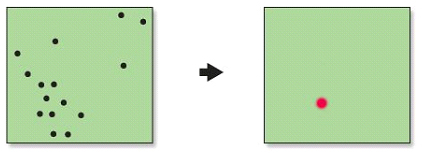
Punt central d'una distribució espacial.
Distància estàndard
La distància estàndard és l'estadístic espacial descriptiu de la dispersió d'una distribució espacial equivalent a la desviació estàndard de l'estadística no espacial. Es calcula de forma anàloga a la desviació estàndard, tenint en compte que hi ha tantes dimensions com coordenades.
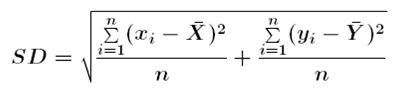
on
xi, yi són les coordenades x i y de cada punt i de la distribució espacial
X-, Y- són les coordenades del centre mitjà de la distribució espacial
n és el nombre de punts
En el cas de considerar pesos espacials, la distància estàndard ponderada es calcula segons l'expressió següent:
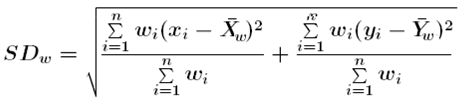
on
xi, yi són les coordenades x i y de cada punt i de la distribució espacial
w, w són les coordenades del centre mitjà ponderat de la distribució espacial
wi és el pes corresponent a cada punt i de la distribució espacial
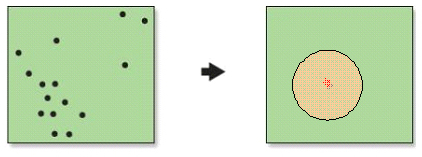
Distància estàndard d'una distribució espacial.
La distància estàndard mesura el grau de dispersió d'una distribució espacial al voltant del seu centre mitjà. S'interpreta com un cercle de radi igual al valor de distància estàndard centrat entorn del centre mitjà. Com en el cas de la desviació estàndard, si la distribució espacial és una distribució espacial normal, aproximadament el 68% dels punts es troben en un radi d'1 distància estàndard al voltant del centre mitjà, el 95% a 2 distàncies estàndard i el 99% a 3 distàncies estàndard.
Distribució direccional (el·lipse de desviació estàndard)
La distribució direccional o el·lipse de desviació estàndard calcula per separat les dues dimensions de la distància estàndard, de manera que, enlloc d'un sol valor indicatiu d'un radi de dispersió entorn del centre mitjà, s'obtenen tants valors com coordenades, que en el cas de dues dimensions s'interpreten com els eixos d'una el·lipse de dispersió. L'eix major d'aquesta l'el·lipse permet determinar la direcció de dispersió predominant.
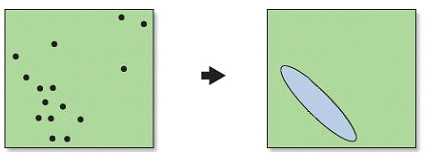
Distribució direccional o el·lipse de desviació estàndard d'una distribució espacial.
El càlcul de la distribució direccional s'efectua, en el cas de dues dimensions, segons les expressions següents:
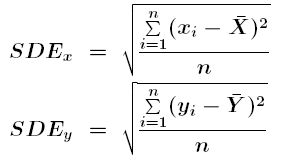
on
xi, yi són les coordenades x i y de cada punt i de la distribució espacial
X-, Y-, són les coordenades del centre mitjà de la distribució espacial
n és el nombre de punts
D'altra banda, l'angle per a determinar l'orientació de l'el·lipse es calcula segons:
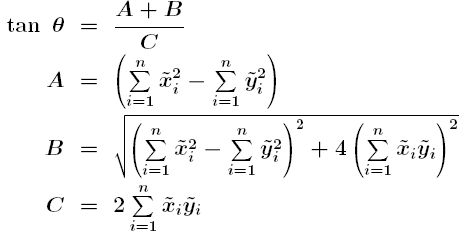
on
x-, y-són les desviacions de cada punt i respecte del centre mitjà
n és el nombre de punts
Mitjana direccional lineal
La mitjana direccional lineal és el vector que indica el centre, longitud i direcció mitjana d'un conjunt de línies.
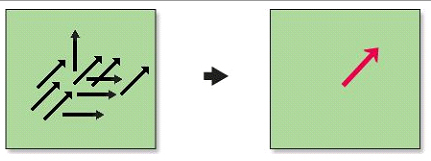
Mitjana direccional lineal d'un conjunt de línies.
L'orientació de la mitjana direccional es calcula segons:

on θi és l'orientació de cada una de les línies
Anàlisi de patrons de variació espacial
La variació espacial dels valors dels atributs d'entitats o observacions s'analitza en gran part a través de l'anàlisi de l'autocorrelació espacial, ja que la variació espacial és gairebé sempre covariació del valor en cada posició d'acord amb els valors en altres posicions, generalment properes.
Autocorrelació espacial
El grau de dependència espacial entre els valors de les observacions en diferents localitzacions es mesura i s'analitza a través d'estadístics o índexs d'autocorrelació espacial, els més coneguts dels quals són l'índex I de Moran i l'índex C de Geary (Cliff and Ord, 1981). Per a l'anàlisi de l'autocorrelació espacial és crític definir la matriu de pesos espacials per tal d'establir el veïnat en què els valors s'influeixen mútuament i quina és la intensitat (el pes) d'aquesta influència en funció de les localitzacions a què corresponen els valors. Els pesos es poden establir de molt diverses maneres, com a simple adjacència o com a funció inversa de la distància, entre d'altres.
Analitzar l'autocorrelació espacial, a més de permetre validar supòsits d'independència o no entre les observacions en diferents localitzacions, equival a identificar patrons de variació espacial presents a les dades. Així una autocorrelació espacial positiva indica un patró espacial agrupat, mentre que una autocorrelació negativa indica un patró dispers i l'absència d'autocorrelació espacial correspon a una distribució espacial aleatòria.
Regressió lineal ordinària
La regressió lineal és una de les tècniques estadístiques més utilitzades per a modelitzar la relació entre variables (Hamilton, 1992). Tot i no ser un mètode d'estadística espacial sovint és el punt de partida per a iniciar una anàlisi de regressióespacial, ja que proporciona un model global simple, a partir del qual contrastar i desenvolupar mètodes més específics d'estadística espacial, com és ara l'autoregressió espacial o la regressió ponderada geogràficament. La forma més comuna de regressió lineal és l'ajust de mínims quadrats.
Regressió ponderada geogràficament
La regressió ponderada geogràficament (Fotheringham, Brunsdon and Charlton, 2002) és una forma de regressió lineal que modelitza relacions que varien en l'espai. La regressió ponderada geogràficament construeix un conjunt de regressions locals per a cada veïnat o ample de banda a l'entorn de cada localització. La mida i forma del veïnat són variables segons el tipus i mètode emprat de regressió ponderada geogràficament (nucli, ample de banda, distància o nombre de veïns).
La regressió ponderada geogràficament evita els problemes de multicolinearitat global, presents en la regressió lineal ordinària de dades espacials, però no pot evitar els problemes de multicolinearitat local que apareixen en dades que presenten patrons de variació espacial amb agrupament espacial. La multicolinearitat local es pot resoldre especificant una distància o un nombre de veïns òptim que cal determinar empíricament.
Anàlisi d'agrupaments de la variació espacial
A diferència de l'anàlisi d'agrupaments espacials, l'anàlisi d'agrupaments de la variació espacial identifica concentracions en l'espai de valors d'un determinat tipus (per exemple, valors alts o baixos, en lloc de concentracions de punts o d'elements en l'espai. La majoria d'anàlisis d'agrupaments de la variació espacial són anàlisis de l'autocorrelació espacial local.
Índex G general de Getis-Ord
L'índex G general de Getis-Ord (Getis and Ord, 1992) mesura el grau de concentració en l'espai de valors alts o baixos. El càlcul de l'índex G general s'efectua segons la fórmula:
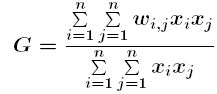
on xi, xj són els valors de l'atribut analitzat en les posicions (o elements) i i j, per a tot i diferent de j
wi j és el pes corresponent a la relació espacial entre les posicions (o elements) i i j
L'índex G general de Getis-Ord segueix una distribució normal de mitjana i desviació estàndard conegudes i per tant la significació del valor obtingut de G es pot avaluar mitjançant el valor estandarditzat z, sabent que valors inferiors a -1,96 o superiors a 1,96 són estadísticament significatius per a un interval de confiança del 95% i permeten rebutjar la hipòtesi nul·la de distribució espacial aleatòria dels valors de l'atribut. Quan el valor estandarditzat de l'índex, z, és significatiu, el signe indica quin tipus de valors presenten concentració espacial. Un valor estandarditzat positiu indica concentració espacial de valors alts, un valor negatiu concentració espacial de valors baixos. El desavantatge és que si la distribució espacial dels valors de l'atribut presenten concentració espacial tant dels valors alts com dels valor baixos, ambdues es cancel·len i no es poden detectar mitjançant l'índex.
L'índex G general de Getis-Ord és apropiat quan els valors de les dades es distribueixen espacialment de manera regular i hom cerca concentracions esporàdiques o puntes de valors alts o baixos que reflecteixen singularitats o anomalies.
Índex Gi* de Getis-Ord
L'índex Gi* de Getis-Ord permet identificar posicions (o elements) destacades amb valors alts o baixos. Així, a diferència de l'índex general G, que proporciona un valor global, l'índex Gi* es calcula individualment per a cada posició (o element geomètric, en cas d'analitzar dades associades a elements). La fórmula de càlcul de l'índex Gi* és la següent:
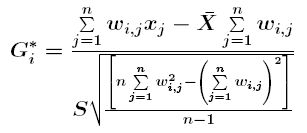
on
xj és el valor de l'atribut analitzat en la posició (o element) j
wi j és el pes corresponent a la relació espacial entre les posicions (o elements) i i j
X- és la mitjana dels valors de l'atribut analitzat
S és la desviació estàndard dels valors de l'atribut analitzat
n és el nombre de punts
L'índex Gi* és directament un valor estandarditzat (valor z) i per tant es pot interpretar directament si és o no estadísticament significatiu. Un valor significatiu positiu de l'índex indica un punt destacat amb valor alt de l'atribut, un valor significatiu negatiu de l'índex indica un punt destacat de valor baix de l'atribut. Els valors de l'atribut estudiat no s'analitzen aïlladament en cada posició, sinó en el context espacial de les posicions relacionades segons la matriu de pesos espacials, Així un punt (o element) per ser un punt destacat de valors alts ha de pertànyer a un context espacial caracteritzat per la presència de valors alts també en les posicions relacionades. Per tant, l'índex Gi* identifica també concentracions de valors alts o baixos, però en lloc de caracteritzar globalment la distribució espacial dels valors de l'atribut proporciona el detall dels punts (o elements) entorn dels quals es produeixen les concentracions. Com que el càlcul de l'índex és individualitzat, les concentracions de valors alts i de valors baixos no s'anul·len mútuament sinó que es posen de manifest totes. L'índex Gi* es pot aplicar a atributs associats a punts o a àrees (polígons o cel·les ràster).
Índex d'Anselin d'autocorrelació espacial local
L'índex d'Anselin d'autocorrelació local o índex I de Moran local (Anselin, 1995) permet identificar agrupacions espacials de valors similars d'un atribut, així com valors anòmals espacials. L'índex I local es calcula individualment per a cada punt (o element) segons l'expressió:
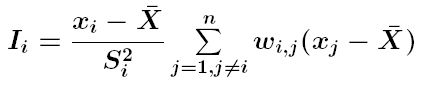
on
xi, xj són els valors de l'atribut analitzat en la posició (o element) i i j, respectivament
wi j és el pes corresponent a la relació espacial entre les posicions (o elements) i i j
X- és la mitjana dels valors de l'atribut analitzat
n és el nombre de punts
Si2 és la variància dels valors de l'atribut analitzat, modificada segons l'expressió següent
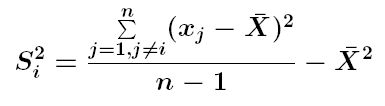
L'índex I de Moran local segueix també una distribució normal de mitjana i desviació estàndard conegudes i per tant la significació del valor obtingut d'I es pot avaluar calculant-ne el valor estandarditzat z. L'índex I local proporciona un valor individual per a cada punt o element, de manera que, mitjançant el valor z corresponent, es pot saber si presenta diferències significatives. Un valor positiu d'I, estadísticament significatiu, indica una posició amb veïns que tenen valors similars, alts o baixos. Un valor negatiu, indica que els valors en posicions veïnes són dissemblants i per tant la posició és un valor espacial anòmal.
Aplicació
L'estadística espacial té nombroses aplicacions en biologia, epidemiologia, geografia, geologia o econometria. Els camps d'aplicació no es limiten a aquells que tracten amb informació geoespacial, sinó que s'estenen a tot tipus d'informació espacial. Així l'estadística espacial s'utilitza també en astronomia, en bioinformàtica o en visió artificial i en robòtica, en particular en el reconeixement de formes.
Al llarg de la dècada de 1990 s'han millorat i desenvolupat nous mètodes d'estadística espacial i, malgrat la major complexitat, la seva utilització va guanyant terreny a l'ús de mètodes d'estadística convencional, inapropiats per a les dades espacials, gràcies a la incorporació d'aquest tipus d'operacions d'anàlisi en els sistemes d'informació geogràfica.
Temes relacionats
- Anàlisi espacial
- Autocorrelació espacial
- Geoestadística
- Interpolació espacial
- Problema de la unitat espacial modificable
- Superfície
Referències
Anselin, L. (1995) "Local Indicators of Spatial Association—LISA", Geographical Analysis, 27(2), 93–115.
Bailey, T.C. and Gatrell, A.C. (1995) Interactive Spatial Data Analysis. Harlow: Longman Scientific & Technical.
Boots, B. and Getis, A. (1988) Point Pattern Analysis. Sage University Paper Series on Quantitative Applications in the Social Sciences, series no. 07–001. Sage Publications.
Clark, P.J. and Evans, F.C.(1954) "On some aspects of spatial pattern in biological populations", Science, 121, 397-398.
Cliff, A.D. and Ord, J.K. (1981) "Spatial and temporal analysis: autocorrelation in space and time" in Wrigley, N. and Bennett, R.J. (eds.) Quantitative geography: a British view, London: Routledge and Kegan Paul.
Dacey, M.F. (1960) "A note on the derivation of nearest neighbour distances", Journal of Regional Science, 2, 81-87.
Fotheringham, A.S.; Brunsdon, C. and Charlton, M. (2002) Geographically Weighted Regression: The Analysis of Spatially Varying Relationships, Hoboken, NJ: Wiley.
Geary, R.C. (1954) "The Contiguity Ratio and Statistical Mapping", The Incorporated Statistician 5 (3), 115–145.
Getis, A. (1984) "Interactive Modeling Using Second-Order Analysis", Environment and Planning A, 16, 173–183.
Getis, A. and Aldstadt, J. (2004) "Constructing the spatial weights matrix using a local statistic", Geographical Analysis, 36, 90–104.
Getis, A. and Ord, J.K. (1992) "The Analysis of Spatial Association by Use of Distance Statistics", Geographical Analysis, 24(3).
Haggett, P. (1965) Locational analysis in human geography, London: Edward Arnold.
Hamilton, L.C. (1992) Regression with Graphics. Brooks/Cole.
Matui, I. (1932) "Statistical study of the distribution of scattered villages in two regions of the Tonami plain, Tayama prefecture", Japanese Journal of Geography and Geology, 9, 251-266.
Meijerink, J.L. (1953) "Interface area, edge length and number of verticesin crystal aggregates with random nucleation", Philips Research Reports, 8, 270-290.
Moran, P.A.P. (1950) "Notes on Continuous Stochastic Phenomena", Biometrika 37(1), 17–23.
Vicent, P.J.; Haworth, J.M.; Griffiths, J.C. and Collins, R. (1976) "The detection of randomness in plant patterns", Journal of Biogeography, 3, 373-380.
Whittle, P. (1954) "On stationary processes in the plane", Biometrika, 41, 434-449.
Lectures recomanades
Boots, B. and Getis, A. (1988) Point Pattern Analysis. Sage University Paper Series on Quantitative Applications in the Social Sciences, series no. 07–001. Sage Publications.
de Smith, M.J.; Goodchild, M.F. and Longley, P.A. (2007). Geospatial Analysis. 2nd edition. Leicester: The Winchelsea Press.
Haining, R.P. (1981) "Spatial and temporal analysis: spatial modelling" in Wrigley, N. and Bennett, R.J. (eds.) Quantitative geography: a British view, London: Routledge and Kegan Paul.
Haining, R.P. (1993) Spatial data analysis in the social and environmental sciences, Cambridge: Cambridge University Press.
Mitchell, A. (2005) The ESRI Guide to GIS Analysis, Vol. 2. Redlands, California:ESRI Press.
Thomas, R.W. (1981) "Point pattern analysis" in Wrigley, N. and Bennett, R.J. (eds.) Quantitative geography: a British view, London: Routledge and Kegan Paul.
